Security Now 984 transcript
Please be advised this transcript is AI-generated and may not be word for word. Time codes refer to the approximate times in the ad-supported version of the show
0:00:00 - Leo Laporte
It's time for security now. Steve Gibson is here and, of course, the topic of the hour, the day, the week, the year probably is the CrowdStrike incident. Steve breaks it down, tells us what happened. Of course, some of this is speculation because we don't know all the details, but he will give you more details than anyone else. This is the place for the CrowdStrike story. Next on Security Now Podcasts you love from people you trust.
0:00:31 - Steve Gibson
This is Twitter.
0:00:36 - Leo Laporte
This is Security Now with Steve Gibson, episode 984 recorded Tuesday. Recorded Tuesday, july 23rd 2024. Crowdstruck it's time for Security Now, the show where we cover your security, your privacy and how things went awry last Thursday and Friday with this guy right here, steve Gibson of GRCcom, our security guru. Hi, steve.
0:01:03 - Steve Gibson
Leo, it's great to be with you for the podcast. That will surprise no one. I was using the phrase this podcast wrote itself, yeah.
0:01:17 - Leo Laporte
But I think there's been a lot of interest from our audience about what your take is, what your explanations are and all of that.
0:01:23 - Steve Gibson
I actually have some that no one has read anywhere else. Good, so look forward to that. Yeah, I think it's going to be interesting, so I, of course I titled this podcast crowd struck and the subtitle is the legend of channel file two, nine one, yes, so yes, we're going to have a name by the way that IT professionals everywhere are learning to hate as they go from machine to machine, deleting them.
0:01:54 - Leo Laporte
Oh my God.
0:01:55 - Steve Gibson
Yes, well, there was so much to talk about because, like, why was that necessary? Why couldn't Windows restore itself?
0:02:02 - Leo Laporte
Why isn't there some escape?
0:02:06 - Steve Gibson
And, of course, the real, ultimate, biggest issue of all is how could CrowdStrike have ever allowed this to happen? I mean, like, what could possibly explain how this got out into the world without them knowing that you know, like what was going on, without them knowing that you know, like what was going on? So, anyway, just this is going to be the one for the record books, probably also in terms of total length, because I ended up at, I think, 22 pages, which is four more than our normal. Yeah, no, 24 pages, yikes. So yeah, we'll.
0:02:42 - Leo Laporte
It's okay, we want this, we want it. Go, baby go.
0:02:46 - Steve Gibson
And believe it or not, leo, something else actually happened last week. No, besides the world basically coming to a grinding halt, so we're going to look at what we know about how the FBI broke into the smartphone belonging to Trump's deceased would-be assassin. Cisco managed to score another of the very rare CVSS 10.0s that you never want to score. It's a serious remote authentication vulnerability, as evidenced by having the maximum 10 out of 10 severity rating, so anyone affected absolutely must update. Also, we now know about the untrusted entrusts' plan for the future, how they're planned to be moving forward once Chrome has said we're not going to be trusting anything you sign after Halloween Also, oh boy.
And was this if now, once upon a time, I would have said the most tweeted? Now, if this was the most emailed to me? Note, because all of our listeners know how I feel about this. Google has lost the anti third party-party cookie battle. Yes, oh boy. So cookies are staying, and now we'll have some things to talk about there. Also. I'm going to share a few more interesting anecdotes from my weekly security now podcast mailings the experience from last week and now I know about this week because 7 000 of our listeners received all of this two hours ago. Uh, you know the, the, the breakdown of topics and the show notes and the picture so you get feedback even before the show, even before you do the show.
0:04:38 - Leo Laporte
Yeah, it happened, that's great. Yes, yeah, exactly that's good. You know, it's like a focus group kind of.
0:04:44 - Steve Gibson
And one of those things was a guy writing from New South Wales, australia, who he actually wrote his letter to me, tweeted it, but I had already finished and produced the podcast before I finally went over to Twitter to tweet about the podcast and I saw that there were some. Anyway, he has something really cool to say about CrowdStrike, which we'll get to next week because hint hint email is a little more quick for getting to me.
0:05:17 - Leo Laporte
Yes, Well, our friends in Australia were the first to bear the brunt of CrowdStrike.
0:05:22 - Steve Gibson
Yes, it was in the afternoon that his world as he knew it ended, poor guy anyway. So I'm going to also. We now know where the seemingly flaky name snowflake came from and why, and then I do have some listener feedback I want to share following up on recent discussions. And then we're going to learn what in literally the world happened to allow CrowdStrike to take down eight and a half million Windows gateways, servers and workstations, to cause the largest IT outage of all time. The largest IT outage of all time. And of course, the reason we're not hearing the details is that you have to imagine that CrowdStrike's attorneys dropped the cone of silence over that. I mean, they probably just went over and yanked the phones out of the wall and said you know what is saying anything?
0:06:22 - Leo Laporte
No one's saying nothing.
0:06:24 - Steve Gibson
And we do have a picture of the week for today's podcast Awesome, which I will talk about a little bit briefly as we get going here.
0:06:33 - Leo Laporte
Very good, well, a really big shoe coming up here in just a bit with Steve Gibson, and we will get right to it. But first a word from our sponsor, panoptica. It's Cisco's cloud application security solution and it gives you end-to-end lifecycle protection for cloud-native application environments. It empowers organizations to safeguard their APIs, their serverless functions, their containers, their Kubernetes environments. Panoptica ensures comprehensive cloud security compliance and monitoring at scale, offering deep visibility, contextual risk assessments and actionable remediation insights for all your cloud assets.
Powered by graph-based technology, panoptica's attack path engine prioritizes and offers dynamic remediation for vulnerable attack vectors, helping security teams quickly identify and remediate potential risks across all their cloud infrastructures. A unified cloud-native security platform minimizes gaps from multiple solutions. It provides centralized management and reduces non-critical vulnerabilities from fragmented systems. And reduces non-critical vulnerabilities from fragmented systems. A unified cloud native security platform those are the words you want to hear. Panoptica utilizes advanced attack path analysis, root cause analysis and dynamic remediation techniques to reveal potential risks from an attacker's viewpoint. This approach identifies new and known risks, emphasizing critical attack paths and their potential impact. Panoptica it provides several key benefits for businesses at any stage of cloud maturity, including advanced CNAP, multi-cloud compliance, end-to-end visualization, the ability to prioritize with precision and context and dynamic remediation and increased efficiency with reduced overheads. Visit panopticaapp to learn more P-A-N-O-P-T-I-C-A panopticaapp to learn more Panopticaapp. We thank them so much for their support of security. Now, all right, steve, the picture of the week is not, uh, not a joke this week.
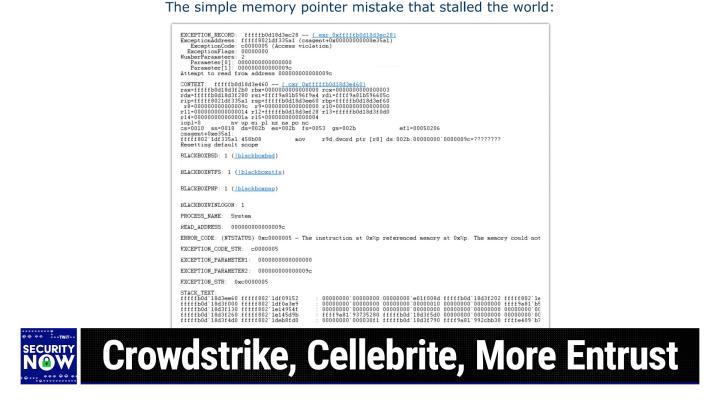
0:08:49 - Steve Gibson
Far from it not so not so funny this time. I gave this this snapshot, uh, the title, the simple memory pointer mistake that stalled the world, and I will be talking about this in gratifying detail at the end of the podcast. But what we see from this now, this is the kind of you know, the crash dump that most people just like what you know it's like it's going to have no meaning whatsoever to almost anyone. But people who understand the machine architecture and and dumps will will see that that this occurred, this, this crash occurred inside something called CS agent, which doesn't take any stretch to know would stand for crowd strike agent, and that there was a function which took two parameters, which this shows up like on the fifth and sixth lines.
0:09:57 - Leo Laporte
This is assembly language, which is why Steve knows what it means, right?
0:10:01 - Steve Gibson
Correct, yeah, correct, right, yeah, correct, yeah, correct. Anyway, so the the function was given a bad parameter and I have a theory as to why, which we'll talk about which caused it to attempt to load 32 bits from where there was no memory, and you can't do that Right, it's one of the things that causes Windows to just give up, and I'll explain why Windows could not recover from this, why an application doing this is different from the kernel doing this and all of that. So, basically, this is a snapshot of the actual crash. Basically, this is a snapshot of the actual crash. It was a simple memory pointer mistake and it took down immediately eight and a half million machines. Windows operating systems.
0:10:56 - Leo Laporte
To the point where they couldn't be rebooted.
0:10:59 - Steve Gibson
They just had to be fixed. Yes, in a way that required, and that's one of the most expensive factors of this right is you had to visit somebody, had to visit every single machine Lord above, oh boy.
So you know, with the glare of what happened last week, you know, still looming over everything, it's a little difficult for us to focus upon anything else and of course we're going to give this our full attention. But there was some other important news that emerged last week which should not be overshadowed. In the wake of the failed attempted assassination of our ex-US President, donald Trump, during his recent campaign rally, the FBI has been attempting to learn all it can about the immediately deceased would-be assassin. They obviously can't ask him for his password. So, 20-year-old Thomas Matthew Crooks was using an Android phone that was password locked. And of course, we've certainly been here before, haven't we? We all remember the San Bernardino mess.
Bloomberg reported that the FBI sought help from the Israeli digital intelligence company Celebrite, which, with offices conveniently located in nearby Quantico, virginia, is known to provide smartphone unlocking technology to US federal agencies. A significant percentage of their business is doing that. Sources familiar with the investigation, who requested anonymity, told Bloomberg that the FBI needed data from the phone to understand Crook's motives for the shooting. You're right, everyone wants to know what was going on. Why it doesn't really matter, but still interesting. So, although the local FBI bureau in Pittsburgh already did have a current license for Celebrite's smartphone cracking software. It was ineffective on Thomas Crook's newest Samsung device, so, undaunted, the FBI reached out to Celebrite's nearby federal team, which is there for the purpose of collaborating with law enforcement when they've got some problems. Within hours of that, celebrite had provided the FBI with the additional support they needed, including some newer, not yet released software, and 40 minutes after that the FBI had Thomas's Thomas's Samsung Android smartphone unlocked and opened for detailed inspection of the shooter's social media browsing, texting whatever history. What's interesting is that in other just it was coincidental really reporting. It appears to be fortuitous for the FBI that Thomas was not using a later model Apple iOS device, since some documents leaked from Celebrite indicate its inability to unlock such devices. 9to5mac picked up on this last Thursday reporting under their headline Celebrite cannot unlock most iPhones running iOS 17.4 and later, they wrote. Leaked documents reveal that Celebrite cannot unlock iPhones running iOS 17.4 and later, at least as of the date of publication, which was April of this year, they said. The company has confirmed that the documents are genuine. Celebrite devices, which are widely used by law enforcement agencies, can crack most Android phones, though there are exceptions.
Celebrite's kit relies on discovering vulnerabilities discovered in iOS and Android, which Apple and Google, of course, then aim to fix and well, discover and resolve. Others also worked to defeat the phone cracking kit, which mostly secure messaging app. Signal scored with a big win in 2021 when it managed to booby trap iPhones to render the kit useless, and we covered that at the time. Back in 2022, 9to5mac managed to obtain user documentation which iPhone models that kit at the time could not unlock. Since then and with this recent document discovery, it was 404 Media that that grabbed updated docs and these these are the the ones dated april of 2024. I got a look at the pdf. It was four panels of grid and explanation that used a lot of jargon that you'd have to have a glossary in order to untangle, so the reporting here is easier to understand. They said, as of that date, that is, april 2024, celebrite had not managed to crack iPhones running iOS 17.4 or later, which today is a very large percentage of iPhones, 9to5mac said. Additionally, the kit cannot currently break into most iPhones running iOS 17.1 to 17.3.1. The hardware vulnerabilities in the iPhone XR and 11 mean those are exceptions. Iphone XR and 11 mean those are exceptions.
The company appears Celebrite. The Celebrite appears to have worked out how to access other iPhones running those versions of iOS. However, as the table says, this capability is coming soon, which means but we don't know how to do it yet, so we don't really know if it's coming ever. The documents are titled Celebrite iOS Support Matrix and Celebrite Android Support Matrix respectively. An anonymous source recently sent the full PDFs to 404 Media, who said they obtained them from a Celebrite customer. They obtained them from a Cellebrite customer For all locked iPhones able to run 17.4 or newer. The Cellebrite document says in research, meaning they cannot necessarily be unlocked with Cellebrite's tools. Today we know from Apple that the majority of iPhones in use today are using iOS 17, though the company doesn't share breakdowns of the specific point numbers. That said, it's a safe bet that a high percentage were uncrackable by Cellebrite as of the date of the document.
A separate table of Android cracking capabilities show that most of them are accessible by the kit. Show that most of them are accessible by the kit, though the Google Pixel 6, 7, and 8 are exceptions. If they were powered down at the time that they were obtained, that's because the cold boot process blocks the exploit that's being used, but they can be accessed if powered up and locked. The same is true of Samsung phones running Android 6, but not those running later versions, indicating that Samsung's implementation of Android 7 managed to introduce a vulnerability which is still present all the way through Android 14, which Celebrite knows about. So, anyway, the Verge summarized the state of play by writing.
Simply, phone hacking companies are overstating their capabilities and, of course, they have motivation to do so. The Verge noted that most newer phones are currently beyond the capabilities of these commercial phone hacking companies. Beyond the capabilities of these commercial phone hacking companies. This could mean that the phone vendors are finally winning this battle by iterating over and constantly improving the security of their solutions. It could also mean that older phones are currently vulnerable because the companies have had more time with them, and that these newer phones may similarly fall in the future.
We can't really say, you know? I guess if I were a betting man, I'd go short on the stock of the hacking companies, since I suspect their remaining days are numbered as the hardware finally becomes impregnable. But please don't take this as a stock tip. I'm not a betting man and I would never encourage anyone else to be. Crowdstrike has just demonstrated that anything can happen. So you never know, with computers and software, having a CVSS score of 10.0 out of a possible 10.0, are vanishingly and blessedly rare.
Unfortunately, last Wednesday, cisco was forced to report and acknowledge one of their own. Ars Technica wrote On Wednesday Cisco discovered a maximum security vulnerability that allows remote threat actors with no authentication to change the password of any user, including those of administrators with accounts on Cisco Smart Software Manager on-prem devices. So that's the key phrase for any of our listeners. And boy, I'm getting an education about just at what a high level our listeners are operating throughout their organizations. So I wouldn't be at all surprised if this means something to some of them. Cisco Smart Software Manager on-prem devices If you have one around and it hasn't been patched since last Wednesday hit pause on the podcast and go do that.
The Cisco Smart Software Manager on-prem resides inside the customer premises and provides a dashboard for managing licenses for all Cisco gear in use. So you know, they created sort of a central management hub which, on the one hand, makes it very convenient for managing everything in your organization. On the other hand, if you happen to have a CVSS of 10.0, which allowed non-authenticated remote users to change passwords at will. That would be a problem, that concentration of power which we keep seeing now. This seems to be a repeating theme right Over and over. Yes, it's convenient, but, boy, when it gets hit it makes the pain much worse. So it's used by customers who can't or don't want to manage licenses in the cloud. Used by customers who can't or don't want to manage licenses in the cloud, which is, you know, the more common approach.
So in their bulletin, cisco warns that the product contains a vulnerability that allows hackers to change any account's password. The severity of the vulnerability, tracked as this is ours speaking tracked as CVE-2024-2419 is rated 10. They write the maximum score. The Cisco Bulletin stated, quote, this vulnerability is due to improper implementation of the password change process. Okay, that seems kind of obvious. An attacker could exploit this vulnerability by sending crafted HTTP requests, in other words a web request, to an affected device. A successful exploit could allow an attacker to access the web UI or API with the privileges of the compromised user. There are no workarounds available to mitigate the threat other than, you know, pulling its plug. But that would probably be a problem too. So it's unclear precisely what an attacker can do after gaining administrative control over the device. One possibility is that the web UI and an API which the attacker gains administrative control over, could make it possible to pivot to other Cisco devices connected to the same network and from there steal data, encrypt files, you know, get up to all the bad stuff that the bad guys do these days.
Cisco reps did not immediately respond to email queries from Ars Technica, and they did. They finished by noting that the post would be updated if a response were to come later. So there's an update. You definitely want to apply it. So again, ultra rare 10.0. If you know anybody who has one of these, make sure they updated since last Wednesday.
Okay, so, in following up on one of our past big points of coverage, several weeks ago, as we all know, after a great deal of hand-wringing and teeth-gnashing on the part of those who run the collective known as the CA Browser Forum, google decided that they could no longer, in good conscience, afford to have their Chrome Web Browser Honor and Trust certificates signed by Entrust moving forward. This was not done, as had been done in the past, due to any egregious, horrific certificate misissuance event, but rather to send a very strong and clear message, not only to Entrust, message to the not only to Entrust, but to the entire community of certificate authorities that there would actually be consequences if they did not live up to the operational and behavioral commitments that they themselves had previously agreed to. Among many other aspects of this, it was not fair for Entrust to be allowed to leave their own misissued certificates in place, and thus saving face with their customers, while other CAs were playing by the self-imposed rules by going to the cost and inconvenience of acknowledging, revoking and reissuing any mistakes that they may have made. So Google's move was and it was meant to be a very clear demonstration that this game would not tolerate any multi-year endemic cheating. The week after we covered this historic event, Todd Wilkinson, entrust's president and CEO, formally apologized and said once again after the industry had lost count of the number of previous times Entrust had said this that they were really, truly and seriously this time going to do better, and I suspect that this time they probably will. But that left us with the question what would Entrust do? In the meantime, when we were talking about this, we explored various paths. We're back here talking about this today because Todd is present with the answer to that question. He signed the following newsflash from them.
Writing to our TLS customers, he said I would like to thank you for your patience as we diligently work to ensure that you will continue to receive uninterrupted public TLS certificate services through Entrust. Today we are ready to share our go forward plans. Firstly, as you likely know, he says, google said that Chrome will no longer accept Entrust public TLS certificates issued after October 31st 2024. Entrust TLS certificates issued prior to October 31st will continue to be accepted through their expiration date. Entrust is committed to returning to the Chrome root store and will keep you informed of developments. We've identified the steps to address Google's decision. We continue to execute our improvement plans and are working closely with the browser community in discussions on our path forward. In the meantime, after October 31st 2024, you can continue to request public certificates and receive certificate services directly from Entrust.
Here is how this will work. We have three bullet points First, continue to order certificates as you have been, under the same pricing model and service level agreements SLAs. Second, rely on Entrust for certificate lifecycle management, verification, support and professional services, as we plan to serve as the registration authority for these certificates. And finally, we will deliver public TLS certificates issued by a CA partner that meets the requirements of the CA Browser Forum and Entrust. He finishes. Today we can share that SSLcom is now an Entrust CA partner.
Sslcom is a global CA founded in 2002 with full browser ubiquity. They are used by businesses and governments in over 180 countries to protect internal networks, customer communications, e-commerce platforms and web services, and we are pleased to partner with them to meet your needs. He finishes. To build resilience into your organization, we recommend that you take inventory and renew your Entrust certificates prior to October 31, 2024. These certificates will be trusted through their expiration date up to 398 days, by which time I'm sure he's hoping this will no longer be necessary. Anyway, he finishes you can renew your certificates through your certificate lifecycle management solution automation tool or the Entrust Certificate Services portal Period. Signed Todd.
Okay, so that answers that question. Quote we will deliver public TLS certificates issued by a CA partner that meets the requirements of the CA browser forum and Entrust Entrust. So it does not appear that any other CA is going to be allowing Entrust to ride on their coattails by signing a new Entrust found SSLcom, an even smaller CA than them who is in good standing, from whom they will purchase and resell web server TLS identity certificates the best estimates I've been able to find on the web are that Entrust does indeed, as we noted previously, have about 0.1% of the total website server business. Sslcom appears to have about half of that at 0.05%, so this deal represents something of a windfall for SSLcom. Entrust will presumably use SSLcom's certificate-issuing machinery in return for paying SSLcom for every certificate Entrust issues under their auspices, so it's a win-win for the time being, but this does also feel like a temporary backstop solution for Entrust.
It feels as though Entrust does indeed plan to work to rehabilitate itself in the eyes of the CA browser community to then have Chrome and any other browsers that may be planning to follow Chrome's lead restore their trust in Entrust's operations and integrity.
So, though Entrust will be losing out on some fraction of their overall certificate revenue, they will likely be able to return the customer relationships or, I'm sorry, retain the customer relationships they've built, and will someday be able to again issue certificates under their own name.
So and of course you can see what, based on what Todd is saying he is saying if you use Entrust before Halloween to reissue a certificate you have, that will span the next 398 days, and they're hoping to be rejuvenated by that point. So maybe they won't even need to fall back on SSLcom, but certainly there will be customers who aren't listening to the know, are completely clueless about any of this happening, who will be coming back to Entrust, you know, later in the year or any time next year as there's. As their previously issued Entrust certificate is getting ready to expire, entrust is saying that's fine, we're not losing you, you can still. You know everyone's pretending that we're still issuing your certificate. You use our portal, you use our UI, but actually the certificate will be coming from SSLcom and, you know, in return for us giving them some piece of the action in order to perform that service for us. So that appears to be what they're up to. And, leo, we're about 30 minutes in.
Yeah, so this would be a good time to take a break, and I'm going to take a sip of coffee to wet my whistle.
0:33:41 - Leo Laporte
I will take a little time out and be back with more. There's. You know what you found a lot of other stuff to talk about. It's not all crowd struck Absolutely not. In fact, google's cookies coming up in just a little bit. Oh boy, oh boy. Our show today, brought to you by Thinkst.
Canary. Nothing stale about Thinkst Canary. It's actually the coolest thing ever. Like a canary in a coal mine, the things canary will warn you when bad guys or gals are inside your network, whether they're from the outside or malicious insiders. It's so cool, though.
These are basically things. Canaries are basically honeypots, but not the not of the old school these are. These are modern honeypots that could be deployed in minutes, can impersonate hundreds of different devices, whether it's a SCADA device, an IIS server, a Linux box with all the services turned on, or just a handful of carefully chosen services. They can even impersonate document files. They call them lures or canary tokens. These can be placed around your network along with the Thinks to Canary Things like PDF. They look like PDF files or DocX files or Excel, whatever you want to name them. We have a few Excel files spread around called employee information. That seems to be a juicy target, but the minute somebody opens them or tries to access the Thinks to Canary's impersonated persona, you will get a notification. No false alerts, just the alerts that matter. So you've set up your Thinks Canaries as an SSH server. Somebody says, oh, I got to get in there. Bingo, bob's your uncle, you got them, just choose a profile. You could change it every day. It's actually kind of fun for your Thinks Canary Register with the hosted console for monitoring and notifications. You can have syslog text email. It supports webhooks. There's an API I mean any kind of notification you want, or all of the above. Then you wait Attackers who breached your network or malicious insiders and other adversaries make themselves known.
They can't help it by accessing the Things Canary. They, you know, they don't think it's a Things Canary. They just look at it and go that's something I want. And then they hit it and you get the information. Now some big banks might have hundreds of these Smaller operations like ours just a handful. But I'll give you a pricing example. Hundreds of these Smaller operations like ours, just a handful, but I'll give you a pricing example. Visit canarytools slash twit C-A-N-A-R-Y dot tools slash twit. For 7,500 bucks a year you'd get five things to canaries with your own hosted console, your upgrades, your support, your maintenance. If you use the code twit in the how did you hear about us box, by the way, you're going to get 10% off, and not just for the first year of your things Canaries, but for life. So that's a great deal.
There's one more thing you should know about. Maybe you're a little skeptical. How can these be as good as Leo says? Try them. You get a two month 60 day money back guarantee for a full refund. So for any reason you say, yeah, it's not for me, you can send them back, get your money back 60 days to do that. But I have to tell you in the seven or eight years that we've been doing ads for the Things Canary, no one has yet not one has yet taken advantage of this guarantee, because everybody loves them.
They do what they say. They're exactly what you need it. They do what they say. They're exactly what you need. It's one thing to have a great perimeter defense, but let's say somebody gets in. How are you going to know they're inside your network? This is how Thinkst Canaries Visit canarytoolstwit, use the offer code twit. Don't forget Canarytoolstwit. And if you have any doubt, just check out Canarytoolslove for a bunch of recent tweets and other messages singing the praise of the Thinks Canary. They are really amazing Canarytoolstweet, and we thank them for their support of the good work Steve does here at Security. Now, we couldn't do it without you. All right, steve? What's all this about cookies?
oh well you really like this whole topics thing that they were going to do, right?
0:37:55 - Steve Gibson
well, it made sense, I understood it. It would have worked um it was privacy forward, yeah oh, absolutely so.
Just just sort of recap, because web servers and web browsers operate query by query, one query at a time, long ago, mozilla designed a simple add on called a cookie. A website server could easily give a browser one of these unique cookies just a meaningless string of data to the browser, but it would subsequently return that, thus identifying itself to the website for all subsequent activities. This simple solution enabled the concept of being logged on to a website which never existed before, and this was the same way that users were previously able to log into other online services. So it was a breakthrough, but that's what it was meant for. As this podcast's longtime listeners know, I've always been very annoyed by the abuse of this simple cookie technology by third parties, since cookies were purely and expressly intended to be used as a means for maintaining locked-on session state and nothing more. But the advent of third-party advertisers, whose ads poked out onto tens of thousands of websites all over the world, meant that their third-party cookies could be used to track and thus profile users as they've moved across the web. And, as you said, leo, for this reason, I've been very excited and hopeful about actually all of Google's sincerely, sincerely repeated attempts to design a workable alternative, which you know they would. They've said once they had that completely eliminate all support for third-party cookies. Now, after that, the web would, in my opinion, finally be operating the way Mozilla originally intended, without cookie abuse, while still offering advertisers the feedback about the visitors to websites who were viewing their ads that they wanted. The only problem was, the achievement of this goal would also collapse the entire internet tracking, profiling and data aggregation industry, and for that reason, it appears that Google has failed in their quest and that the tracking and profiling industry has won.
Yesterday, monday, july 22nd, google's VP of the Privacy Sandbox Project effectively admitted defeat. Anthony Chavez's posting was titled quote A New Path for Privacy Sandbox on the Web unquote. Well, you know the path they were on was the right path, so a new path is not going to be any writer. Understanding what Anthony is really saying here requires a great deal of reading between the lines, though we focused enough on this in the past that I think I know what actually happened. Anyway, first here's what he wrote. He said we developed the Privacy Sandbox with a goal of finding innovative solutions that meaningfully improve online privacy while preserving an ad-supported Internet that supports a vibrant ecosystem of publishers, connects businesses with customers and offers all of us free access to a wide range of content. Right, he says.
Throughout this process, we've received feedback I bet you have from a wide variety of stakeholders, including regulators like the uk's competition and markets authority, the cma that we were talking about not long ago and Information Commissioner's Office, the ICO, publishers, web developers and standards groups, civil society and participants in the advertising industry. This feedback has helped us craft solutions that aim to support a competitive and thriving marketplace that works for publishers and advertisers and encourage the adoption of privacy-enhancing technologies. Early testing from ad tech companies, including Google, has indicated that the Privacy Sandbox APIs have the potential to achieve these outcomes, and we expect that overall performance using Privacy Sandbox APIs will improve over time as industry adoption increases. At the same time, we recognize this transition requires significant work by many participants and will have an impact on publishers, advertisers and everyone involved in online advertising. In light of this, we are proposing an updated approach that elevates user choice. That's called putting a good face on the problem.
They said, instead of deprecating third-party cookies, we would introduce a new experience in Chrome that lets people make an informed choice that applies across their web browsing, and they'd be able to adjust that choice at any time. We're discussing this new path with regulators and will engage with the industry as we roll this out. They said, as this moves forward, it remains important for developers to have privacy-preserving alternatives. We'll continue to make the Privacy Sandbox APIs available and invest in them to further improve privacy and utility. We also intend to offer additional privacy controls, so we plan to introduce IP protection into Chrome's incognito mode.
We're grateful to all the organizations and individuals who have worked with us over the last four years to develop, test and adopt the Privacy Sandbox, and as we finalize this approach, we'll continue to consult with the CMA, ico and other regulators globally. We look forward to continued collaboration with the ecosystem on the next phase of the journey to a more private web. And of course, the problem is none of the other stakeholders want a more private web, so third-party cookies will remain in Chrome and it really appears unlikely that technologies such as the privacy-preserving topics will gain any foothold, since the advertising tracking, profiling and data aggregating industries want everything they can get their hands on, and they appear to have won this battle by crying to European regulators that it's no fair for Google to take this away from them, and whether websites begin insisting that their users enable what is going to be called. You know whatever they end up calling it, you know across their site's content. You know like oh, you seem to have this turned off. If you want to use this content, please turn it on.
0:46:06 - Leo Laporte
Oh, and while you're at it, what's a good email address for you? But most people who certainly listen to this show turn off third-party cookies. Is that setting honored in all browsers?
0:46:15 - Steve Gibson
Yes, Okay, yes, and I can vouch for that because this has been a hobby horse of mine for quite a while. Been a hobby horse of mine for quite a while. If you were to Google GRC cookie forensics, it takes you to a series of pages I created years ago. Um, and actually, um, I'm seeing that, uh, third party cookie behavior is down among GRCcom visitors. Um, that cookie, yes, you're showing it. Now that cookie forensics page is actually able to verify the percentage. Yeah, so that used to be up at about 80% and now, as we can see, it says 17.8% of all GRC visitors have persistent third-party cookies enabled, and that's of 21,767 unique GRC visitors. So people are turning it back on. No, no, no, scroll down and look at the Apple number, because Apple is the only one who's always had this off by default. So, again, this shows the tyranny of the default.
0:47:32 - Leo Laporte
Apple Safari visitors are down below 2% of them but a but but, it's on by default and that says that a lot of people are turning it off, and that's because they listen to this show.
0:47:49 - Steve Gibson
They know to turn it off. That's good, yes, and and if you scroll down to the cookie forensics, there is a let's see which one there number three, it'll actually do. Do it that? You just tested your browser to look at your, your third-party cookie handling across the board?
0:48:06 - Leo Laporte
and yours is completely locked down because I listen to you. I have always turned off third-party cookies yep yep, good job. So you know a lot about this.
0:48:17 - Steve Gibson
Uh, yeah this has been a focus of mine because it's just just really, you know, irks me that this has been so abused. And what's interesting is back when I originally designed it, that forensics test. You'll notice it has eight different types of cookies it looks for of each type. It's because browsers, so there's page CSS script embedded image, icon, iframe and object.
Browsers used to be broken. They were actually. Even if you turned them off, some of them would still be on. So this allowed us to profile whether browsers were even operating correctly, and back in those early IE6 days, they weren't.
0:49:02 - Leo Laporte
Well, the other point I think is really good to take from this page is that first-party cookies are okay. That is a necessary system on the internet. You don't want to turn off all cookies.
0:49:13 - Steve Gibson
You can't log on to a website without first-party cookies.
0:49:17 - Leo Laporte
And that's a convenience. It's the third-party cookies that are a problem, and it's unfortunate because I think these cookie banners from the UK and the EU have kind of taught people all cookies are bad, but that's not the case. Nope, nope yep anyway.
0:49:37 - Steve Gibson
So what I think must have happened, leo, is because we saw the kind, we saw the writing on the wall. It was the eu and their regulators that were under pressure from, from, from advertising.
Yeah, yes, the advertisers and the trackers and data aggregators is like, hey, this is our business, you can't. You know, google just can't come along and take away our business. It's like, well, unfortunately, their business should not be ours and these have been mixed up, so I don't know how to really read what Google's thoughts are in the future. They've got an API that requires, in order for it to work, they had to force everyone to use it, otherwise no one's going to use it. No one is going to make a change, right? So I think we're stuck with third-party cookies.
0:50:33 - Leo Laporte
So again, if you Google GRC cookie forensics, you can see this page, free page on Steve's site. That's a really useful and informational page that I wish all of these regulators would read. To be honest with you, oh well.
0:50:50 - Steve Gibson
They don't want it to be there, they just want to, you know, skulk around in the dark and aggregate data about us. Okay, so I thought that our listeners would enjoy learning what I've been learning from the exercise of sending email in this era of hypervigilant, anti-spam and antiviral email protection measures. Anti-spam and anti-viral email protection measures. Last Tuesday, I found three causes for the trouble that I mentioned in getting the email to our listeners. First, it turns out by sheer coincidence, the thumbnail image of the picture of the week was indeed triggering a false positive detection from some AV scanners. Later that evening, I removed the thumbnail from the email and resent the email to the 83 subscribers who had not received it due to an AV rejection. False positive, and that time only three of them bounced. So it was indeed just a coincidental thumbnail image. There's nothing I can do about it, and this week's thumbnail had no problem.
Second, the second issue was after carefully examining the feedback that I was receiving from some of the AV tools, I saw that some of them were complaining about the email containing a banned URL. The exact quote was contains a URL listed in the URIBL blacklist, and guess what? The URL was Polyfillio. I used that phrase in the email and I didn't like put square brackets around the dot, as I should have done. So, yep, you got me on that one. From now on, I'll make sure that any dangerous URLs are rendered non-dangerous in any email that I send. But so, yeah, kind of props for the AV guys for catching it, even though it was a pain.
The third and final discovery was a complaint about invisible text in the email, and so I stared at my code. I hand wrote the HTML. Like what? There's no invisible text, but it turns out I had taken an innocuous looking line from several discussions about composing email for better viewing on a wider range of devices, about composing email for better viewing on a wider range of devices. It was an HTML div line with its display style set to none and a font point size of zero. I don't know why.
0:53:47 - Leo Laporte
That's a tracking pixel.
0:53:48 - Steve Gibson
Yes, Well, no, but no no, there was no URL.
0:53:51 - Leo Laporte
It doesn't phone home.
0:53:53 - Steve Gibson
There was no text, there was no URL. It doesn't phone home. There was no text, there was no URL, but what it did was it basically triggered another false positive, and I removed it from this week's mailing and I didn't have any trouble at all. I should note, however, that it was mostly our listeners using Hover's email hosting service that were rejecting and bouncing last week's SecurityNow email back to me. The bounce message was 5.7.1 message blocked due to the very low reputation of the sending IP. It's like okay, well, yeah, true, I'm just getting started here at GRC sending these kinds of mails, so that was sort of expected, and it doesn't make me love Hover any less. They're still my beloved domain supplier.
0:54:51 - Leo Laporte
Well, and you said it was Clam. Av, which makes sense that they would use as an antivirus scan. It's a free, open source program.
0:54:59 - Steve Gibson
Yes, although this is I'm not sure where the reputation of the sending IP comes from. Oh right, yeah. I did confirm with one of our listeners, Paul Sylvester, who I exchanged email with. He added security now at GRCcom and mail-manager at gmailcom to his allow list. There is an allow list at Hover in the webmail system, so you can do that. Yes, and today I only got four bounces back from hover. Everybody else apparently looked into it and fixed it.
0:55:41 - Leo Laporte
Do you use DKIM and SPF to use the authentication?
0:55:46 - Steve Gibson
You don't even get off the ground unless you've got. Spf DKIM and SPF.
I have them all SPF, dkim and SPF. I have them all. The problem is in the same way that I'm signing all of my Spinrite XEs, yet Windows Defender still sometimes complains Similarly, even though my email is signed. If you don't have reputation, reputation matters, and so, grccom, you know I've never been doing anything like this. I mean even 7,000 pieces of email this morning. 7,000 pieces of email went out to Security Now listeners and it almost went perfectly. So it was much better than last week and I imagine it'll only you know keep getting better in the future and you build.
0:56:35 - Leo Laporte
You build reputation as you use it over time.
0:56:38 - Steve Gibson
Yeah, over time, right, yeah. Jeff Gerritsen in Yakima, washington. He said one of snowflakes primary target markets is data warehouse applications. Traditionally, data warehouse databases are organized as a star schema with a central fact table linked to multiple dimension tables that provide context. A variation is when one or more dimensions have enough internal complexity that it makes sense to break some attributes out into sub dimensions. Then the star schema diagram starts looking more complex, more like a snowflake. So a snowflake schema is a more general case of a star schema. And he said hope that helps. Love the show okay jeff.
Thank you, that is. That is indeed where the snowflake name came from. I also got a kick out of a much more playful posting uh. At the moment, of course, uh. As we know, snowflake has a problem because some 350 of their clients had all of their data stolen from them, which does not make them happy. But 10 years ago, back in 2014, a Snowflaker named Marcin Zukowski, who is a co-founder and VP of engineering at Snowflake, posted the following to Snowflake's blog of Engineering at. Snowflake posted the following to Snowflake's blog.
He wrote one of the questions that we get the most is why did you decide to name the company Snowflake? He says. I'm sure our marketing department has their opinion of what we should say, but let me give you the real story. The name Snowflake just fits us in several ways and he has four bullet points. First, snowflakes are born in the cloud, for a data warehouse built from the ground up for the cloud. That's very important. Second, we love the snow. Excuse me, he says we love the snow.
Most of our founding team and even our first investor love to spend time up in the mountains in the winter. They even convinced me to try skiing and took me on a black run my first day and third. He said each snowflake is unique. One of the really cool things about our architecture is that it lets you have as many virtual warehouses as you need all in one system, each of which has exactly the right resources to fit the unique needs of each set of your users and workloads, and conveniently. Snowflake happens to have a meaning in the world of data warehousing. A data warehouse schema organized as multiple dimension tables surrounding a set of fact tables is one of the data architectures that we can support. So now we know.
0:59:47 - Leo Laporte
Be more than we wanted to know actually.
0:59:51 - Steve Gibson
Well, we were making fun of them last week so it's only fair to explain where they came up with, like as flaky a name.
0:59:59 - Leo Laporte
It's not completely out of the blue, no Well, it is, it's out of the cloud.
1:00:04 - Steve Gibson
A listener, requesting anonymity, shared his experience following the recent CDK Global dealership outage. He said many thousands of records during the outage and since they were down, all transactions failed. The article you mentioned last week about the accounting office needing to deal with a mess is spot on. As I'm listening to the podcast about this mess a couple of days after it came out, I'm in the middle of crafting SQL scripts to fake out the system to make it think that items that the dealership accounting offices had to manually handle were already posted across to CDK so that they would not double book them. That's basically anything that happened in June. Because the accounting offices had to close the books at the end of June, cdk cut all third-party interface access during their restoration. Our interface access was finally restored a few days ago. However, as part of the process of restoring our interface access, cdk changed our interface credentials, which had remained the same for 15 years. Yes, 15 years. So regards from an anonymous listener.
John Muser, writing about the polyfillio mess and the use of resource hashes, wrote one thing I feel you should have mentioned. With the SRI system you know that that's the system for tracking hashes of downloaded resources is that this does invalidate one of the reasons a web developer might use externally hosted resources. Suppose there's a vulnerability found in one of the external libraries. In that case the website developer will have to update their URL and the hash before the vulnerability is fixed for their site. If they blindly pull the latest compatible version, they will always have the latest bug fixes. There will always be a difficult balance to be struck between convenience and security, and John's right of course. Convenience and security, and John's right, of course. As I noted last week, the only way to safely verify a downloaded resource against its known hash is if that resource never changes. That can be assured only by specifying the resource's exact version number. But, as John notes, that also means that the web pages using that pinned version release will not be able to automatically receive the benefits of the version being moved forward as bugs are found and fixed. So choose your poison Either tolerate a bug that may later be discovered until you're able to update your website's the version that your website is pulling, or go for the latest automatically and hope that you never download malware by mistake, as a Polyfillio debacle showed was possible.
Simon, an Aussie in the UK, as he describes himself, he says I suggest MITM now stand for miscreant in the middle and I like that one a lot. We don't need to change the abbreviation away from MITM, just the first M now stands for miscreant. Thank you, simon. Ryan Frederick said he wrote.
You said on this week's show that you will make a Copilot Plus blocker app in assembly if Microsoft ever releases it. At this time the only Copilot Plus certified PCs are ARM, while you're an x86 assembly developer. That said, if anyone can learn ARM assembly in a week and release a patching program, it's you, okay. So first, ryan makes a very good point that there's no way ARM-based Windows machines will not also be able to emulate Intel x86 family instructions to run all existing Intel-based apps. We know they'll have a problem with drivers because that's because they're down in the kernel Apps they're going to be able to run and Microsoft has indicated that Copilot Plus with recall will be coming to Intel platforms just as soon as they're able to make it happen. So I'm pretty sure that my style of app development will not be threatened and it will be a long time, as in decades, before the population of ARM-based Windows desktop becomes important or significant or, you know, threatens Intel. So I think we're probably going to be okay, which is good, because I don't think I would develop an app in ARM assembly for Windows, if that's what it took Chris Quinby in Riverdale.
He said I'm a week behind the podcast, finishing an audio book. I'm also late in sending this feedback so it may have already been sent to you by hundreds of listeners. No, in episode 982, which was just two weeks ago, so he's not that far behind. You talked about a Linux daemon that would monitor logs and modify firewall rules to block IP addresses that made unwanted connection attempts to the computer. You stated that you could not think of any reason why that should not be in place on every computer that accepts incoming connections. So he says one downside is that active blocking can be used to create a denial of service condition. If the attacker notices the active blocking, they can spoof the source addresses for connection attempts to make the server start blocking all inbound connections. Since the connection does not need to be real, he has in quotes the TCP connection handshake is not required. There can be a balance where the new firewall rules can have a time limit before they're removed but if left to block forever, a server can effectively be disconnected from the internet. Signed Chris.
Okay, so generically I completely agree with Chris. He's absolutely correct that blocking incoming connections by IP opens up the possibility of creating deliberate denial of service attacks by deliberately filling up the block list of IP addresses. But I'm a little unsure what he meant by when he wrote. Since the connection does not need to be real, the TCP connection handshake is not required Because I believe it is, tcp-based services will not consider a client to be connected until the three-way handshake has been acknowledged. It's true that the client can provide data along with the final ACK in its reply to the server's SYN ACK.
But those round trips definitely do need to occur before the server's TCP IP stack decides that it has a valid connection. And of course you can't get round trips back and forth if you're spoofing your source IP, because the acknowledgement packet will go off to the IP that you're spoofing, not back to you, so you're unable to complete the handshake. So while UDP services, which do not have a TCP three-way handshake, could definitely be spoofed to create such an attack, tcp-based services such as SSH which is what we were talking about, the open SSH flaw fortunately cannot be spoofed. So blocking based upon authentication failures would be spoof proof for them. And Leo, this has brought us to the one hour point and we are now ready to talk about crowdstruck. Oh, let's do our third, our third break, and then, uh, we're going to plow into exactly what happened.
1:09:19 - Leo Laporte
I know everybody's really interested in your take on this, so I can't wait. But first a word from our sponsor, venta. Venta. You know Venta right. Whether you're starting or scaling your company's security program, demonstrating top-notch security practices and establishing trust is more important than ever right. Vanta automates compliance for SOC 2, iso 27001, and more, saving you time and money while helping you build customer trust. Plus, you can streamline security reviews by automating questionnaires and demonstrating your security posture with a customer-facing trust center, and it's all done for you all, powered by Vanta AI. Over 7,000 global companies use Vanta, like Atlassian, flowhealth, quora. They use Vanta to manage risk and to prove security in real time. It's a real advantage. Get $1,000 off Vanta when you go to vantacom. Vantacom slash security now that's vantacom slash security now $1,000 off Vanta. It's just good business Compliance, as they say on their billboard. That doesn't sock too much. I love that. All right, back to CrowdStruck.
1:10:44 - Steve Gibson
I'm very curious what you have to say. The legend of Channel File 291. So I start this in the show notes with a picture from a listener. This shows the blue screens of death at the deserted Delta terminal of the Seattle Tacoma Airport, which was taken Friday morning by a listener who has been listening since episode one, and we see three screens. It looks like maybe there's someone back in the distance there, sort of behind one of the screens, facing away from us, but otherwise there's nobody in line.
1:11:23 - Leo Laporte
There's an empty wheelchair 4,000 flights canceled. 4,000 flights canceled. That's mine, for.
1:11:31 - Steve Gibson
Delta alone.
1:11:33 - Leo Laporte
By the way, Paul Theriot, being a little bit uh of a pedant, says that's not the blue screen of death, that's a recovery screen. But you know what?
1:11:43 - Steve Gibson
It's a blue screen of death. Okay, paul, point taken. So it's fortunate that, uh, grc's incoming email system was already in place and ready for this CrowdStrike event.
1:11:57 - Leo Laporte
I bet you got the mail.
1:11:59 - Steve Gibson
Oh did I, and I'm going to share some right from firsthand accounts from the field, because it enabled a number of our listeners to immediately write last week to send some interesting and insightful feedback.
1:12:12 - Leo Laporte
A lot of our listeners, I'm sure, have very sore feet going from machine to machine all weekend.
1:12:17 - Steve Gibson
Holy cow. In one case, 20,000 workstations. Oh, and these people don't hang out on Twitter, so email was the right medium for them. Brian Tillman wrote I can't wait to hear your comments next week about the current cloud outages happening today. My wife went to a medical lab this morning for a blood test and was turned away because the facility cannot access its data storage Wow. Another listener wrote good morning. I'm new to this group only been. I love this. I'm new to this group, only been listening for the last eight years. Oh, newbie, that's right, you're going to have to go back and catch up, my friend.
He says I'm sure CrowdStrike will be part of next week's topics. Uh-huh, he said. I would love to hear your take on what and how this happened. I'm still up from yesterday fixing our servers and end users' computers. I work for a large hospital in central California and this has just devastated us. We have fixed hundreds of our critical servers by removing the latest file pushed by CrowdStrike and are slowly restoring services back to our end users and community. Thank you for all you do, keeping us informed and educated of issues like this, looking forward to 999 and beyond.
1:13:43 - Leo Laporte
Oh, I like. That could be our new slogan 999 and beyond, I like it.
1:13:49 - Steve Gibson
That's it.
Tom Jenkins posted to GRC's news group. Crowdstrike is a zero-day defense software, so delaying updates puts the network at risk. I don't know how they managed to release this update with no one testing. It Seems obvious at this point Even casual testing should have shown issues. And of course Tom raises the billion-dollar and I'm not probably exaggerating the billion dollar question how could this have happened? And we'll be spending some time on that in a few minutes. But I want to first paint some pictures of what our listeners experienced firsthand. Tom's posting finished with. We had over 100 servers and about 500 workstations offline in this event, and recovery was painful. Their fix required the stations to be up. Bad ones were in a boot loop that, for recovery, required manual entry of individual machine bitlocker keys to apply the fix, for their maintainers to be able to get to the file system even after being booted into safe mode, because safe mode's not a workaround for BitLocker.
Seamus Maranon, who works for a major corporation which he asked me to keep anonymous, although I asked for permission. He told me who it is but asked for anonymity there. He said for us the issue started at about 1245 am Eastern Time. We were responding to the issue and get a load of this response and the way his team operated. So the issue started for him at 1245 am Eastern Time. He said we were responding to the issue by 1255, 10 minutes later and had confirmed by 105 am that it was a global level event and communicated that we thought it was related to CrowdStrike. We mobilized our team and had extra resources on site by 1.30 am, so 25 minutes later. The order of recovery we followed were the servers, production systems, our virtual environment and finally the individual PCs. In all there were about 500 individually affected systems across a 1,500-acre campus. We were able to get to 95% recovery before our normal office hours started and we were back to normal by 10 am. Okay now I am quite impressed by the performance of Seamus' team. To be back up and running by 10 am the day of after 500 machines were taken down across a 1,500-acre campus, taken down in the middle of the night, is truly impressive and I would imagine that whomever his team reports to is likely aware that they had a world class response to a global scale event Since, for example, another of our listeners in Arizona was walking his dog in a mall because it's too hot to walk pets outside during the day in Arizona. He took and sent photos of the sign on Dick's Sporting Goods the following day, on Saturday, stating that they were closed due to a data outage. So it took, you know, many other companies much longer to recover.
A listener named Mark Hull shared this. He said Steve, thanks for all you do for the security community. I'm a proud Spinrite owner and have been an IT consultant since the days of DOS 3 and NetWare 2.X. Wow, he said uh-huh. He said I do a lot of work in enterprise security, have managed CrowdStrike, write code and do lots of work with SCCM. He says parens MS endpoint management as well as custom automation. So I feel I have a good viewpoint on the CrowdStrike disaster. He says CrowdStrike is designed to prevent malware and, by doing so, provide high availability to all our servers and endpoints. The fact that their software may be responsible for one of the largest global outages is completely unacceptable. As you have said many times, mistakes happen, but this kind of issue represents a global company's complete lack of procedures, policies and design that could easily prevent such a thing from happening. Now, of course, this is. You know what do they call it? Something quarterbacking.
1:19:09 - Leo Laporte
Yeah, monday night quarterback.
1:19:11 - Steve Gibson
Yeah, okay, right, 2020 hindsight, hindsight, yeah and I do have some explanations for this, which we'll get to anyway. He said, given the crowd strike is continually updated to help defend against and I should just say I know no one's disagreeing with him and you know congress will be finding out before long. You know what happened here. But but he said, given the CrowdStrike is continually updated to help defend against an ever changing list of attacks, the concept of protecting their customers from exactly this type of issue should be core to their design. Always have a pilot group to send out software before you send it to everyone. He says. I work with organizations with easily over 100,000 users. If you don't follow these rules, you eventually live with the impact. In the old days, companies would have a testing lab of all kinds of different hardware and OS builds where they could test before sending anything out to production. This would have easily caught the issue, he says. Now it seems that corporations have eliminated this idea. Since this is not a revenue generating entity, they should research opportunity cost. He says. With the onset of virtualization, I would argue, the cost of this approach continues to decrease. And again, at this point this is speculation because we don't understand how this happened. But he says, since it appears this was not being done. Another software design approach would be to trickle out the update, then have the code report back metrics from the machines that received the update at some set interval, for instance every 5, 10, 30 minutes. The endpoints could send a few packets with some minor reporting details, such as CPU utilization, disk utilization, memory utilization. Then if CrowdStrike pushed an update and the first 1,000 machines never reported back after 5 minutes and the first thousand machines never reported back after five minutes, there would be some automated process to suspend that update and send emails out to the testing team. In the case of endpoints that check back every 10 minutes, you could set a counter and blah, blah, blah. Anyway, he goes on to explain, you know, the sorts of things that make sense for means of preventing this from happening and yes, I agree with him completely. From a theoretical standpoint. There are all kinds of ways to prevent this and again, as I said, we'll wrap up by looking at some of that in detail.
Samuel Gordon Stewart in Canberra, australia, wrote. He said here in australia it was mid-afternoon on a friday most broadcast media suffered major outages limiting their ability to broadcast news or anything else for that matter. Sky news australia had to resort to taking a feed of Fox News as they couldn't even operate the studio lights. They eventually got back on air with a limited capacity, from a small control room in Parliament House. The national government-funded broadcaster, abc, had to run national news instead of their usual state-based news services and couldn't play any pre-recorded content, so reporters had to read their reports live to camera. A lot of radio stations were still unable to broadcast even Friday night.
Supermarkets had their registers go down. One of the big supermarkets near me had half their registers offline. A department store nearby had only one register working. Train services were halted as the radio systems were all computerized. Airports ground to a halt. Half a dozen banks went offline. Telecommunication companies had outages. Many hospitals reverted to paper forms. A lot of state government systems seemed to be affected, but the federal government seem less impacted, and who knows how long it will take for IT departments to be able to physically access PCs which won't boot so they can implement the fix, as you would say, steve, about allowing a third party unilaterally updating kernel drivers worldwide whenever they want. What could possibly go wrong? After I thanked Samuel for his note, he replied with a bit more writing in my own workplace. We're offline until Monday. I think we got lucky because our network gateway was the first to take the update and failed before anything else had a chance to receive the update.
1:24:01 - Leo Laporte
So it took them offline, but fortunately it stopped the update for everybody else.
1:24:07 - Steve Gibson
That's good, he said nothing will get fixed until the head office looks at it. But I think they'll be pleasantly surprised that only a couple of devices need fixing and not dozens or more. Not my problem or role these days, although I did foolishly volunteer to help Good man and I saw the following on my Amazon app on my iPhone. It said I got a little pop-up. That said, a small number of deliveries may arrive a day later than anticipated due to a third-party technology outage.
Yeah, yep. Meanwhile, in the US, almost all airlines were grounded, with all their flights canceled. One, however, was apparently flying the friendly skies all by itself.
1:24:55 - Leo Laporte
Before you repeat this story, it's been debunked.
1:24:58 - Steve Gibson
I'm not surprised.
1:24:59 - Leo Laporte
Yeah, it didn't seem possible yeah.
1:25:02 - Steve Gibson
Yes, digital Trends reported under the headline, a Windows version from 1992, is saving Southwest's butt right now. Anyway, yes.
1:25:17 - Leo Laporte
Southwest got saved because they didn't use CrowdStrike is how they got saved, not because they were using Windows 3.1.
1:25:21 - Steve Gibson
Exactly, there are companies all over the world who are not CrowdStrike users, exactly, and so it was only those who had this csagentsys device driver loading at boot time in their kernel that had this problem. Yeah, yeah, so, and and I think that this was made more fun of because in the past, remember that, um, uh, the southwest airlines has come under fire for having outdated systems. Yes, but not not that. Yes, they had scheduling systems they hadn't updated for a long time.
1:26:02 - Leo Laporte
It's an interesting story and somebody, uh, on mastodon kind of went through it, and it really is, if this happens a lot in journalism nowadays. Somebody tweeted that the southwest scheduling software looked like it was windows 95. It wasn't, but looked that way. It got picked up and like telephone it got elaborated to the point where digit trends and a number of other outlets, including, I might add, myself, reported this story and then we found out it was you know, Southwest never confirmed it.
1:26:33 - Steve Gibson
Yeah, and really I mean, even I'm having problems today on Windows 7.
1:26:39 - Leo Laporte
Yeah, Because you know, increasingly things are saying what are you thinking, gibson?
1:26:44 - Steve Gibson
Like what is wrong with you?
1:26:46 - Leo Laporte
So yeah, you have to really, really work hard to keep 3.1 up and running. I think yeah.
1:26:53 - Steve Gibson
So I was initially going to share a bunch of TechCrunch's coverage, but then yesterday, uh, catalin, uh Simpanu, the editor of the Risky Business Newsletter, produced such a perfect summary of this event. Um, that, only one important point that TechCrunch raised made it later in today's podcast, which I'll get to in a minute. But first here's Catalan's summary, which was just, it's perfect. So he writes around 8.5 million Windows systems went down on Friday in one of the worst IT outages in history. The incident was caused by a faulty configuration update to the CrowdStrike Falcon security software that caused Windows computers to crash with a blue screen of death. Paul, we realize that's not what it is, thank you.
Since CrowdStrike Falcon is an enterprise-centric EDR, the incident caused crucial IT systems to go down in all the places you don't usually want them to go down. Outages were reported in places like airports, hospitals, banks, energy grids, news organizations and loads of official government agencies. Planes were grounded across several countries. 9-11 emergency systems went down, hospitals canceled, medical procedures, atms went offline, stock trading stopped, buses and trains were delayed, ships got stuck in ports, border and customs checks stopped, windows-based online services went down. He says, for example, icann and there's even an unconfirmed report that one nuclear facility was affected. The Mercedes F1 team, where CrowdStrike is a main sponsor, had to deal with the aftermath, hindering engineers from preparing the carts for the upcoming Hungarian GP. Heck, he wrote. Even Russia had to deal with some outages. Whoops, I guess they're not quite Windows-free yet. Over there he says it was a cluster you-know-what on so many levels that it is hard to put into words how much of the world was upended on Friday, with some outages extending into the weekend. Reddit is full of horror stories where admins lost their jobs, faced legal threats or were forced to sleep at their workplace to help restore networks. There are reports of companies having tens of thousands of systems affected by the update.
The recovery steps aren't a walk in the park either. It's not like CrowdStrike or Microsoft could have shipped a new update and fixed things in the span of a few minutes. Instead, users had to boot Windows into safe mode and search and delete a very specific file mode and search and delete a very specific file. The recovery cannot be fully or remotely automated and an operator must go through the process on each affected system. Microsoft has also released a recovery tool which creates a bootable USB drive that IT admins can use to more quickly recover impacted machines, but an operator still needs to be in front of an affected device.
For some super lucky users, the BSOD error corrected itself just by constantly rebooting affected systems. Apparently, some systems were able to gain short enough access to networking capabilities to download the fixed CrowdStrike update file and overwrite the old buggy one. However, this is not the universal recommended fix. There are people reporting that they managed to fix their systems after three reboots, while others needed tens of reboots. Needed tens of reboots. It took hours for the debug information to make its way downstream, meaning some of the world's largest companies had to bring their businesses to a halt, losing probably billions in the process and he said extremely rough estimation, but probably in the correct range, he writes. Unfortunately, the Internet is also full of idiots willing to share their dumb opinions. In the year of the Lord, 2024, we had people argue that it's time to ditch security products since they can clause this type of outage. Oh yes, that's the solution. Eye roll.
But CrowdStrike's blunder is not unique, or new for that matter. Something similar impacted loads of other vendors before, from Panda Security to Kaspersky and McAfee. Ironically, crowdstrike's founder and CEO, george Kurtz, was McAfee's CTO at the time, but don't go spitting conspiracy theories about it. It doesn't actually mean that much. He writes stuff like this tends to happen, and quite a lot. As an InfoSec reporter, I stopped covering these antivirus update blunders after my first or second year because there were so many and the articles were just repetitive. Most impact only a small subset of users, typically on a particular platform or hardware specification. They usually have the same devastating impact, causing BSOD errors and crashing systems, because the nature of security software itself, which needs to run inside the operating system kernel so it can tap into everything that happens on a PC.
Crowdstrike released an initial post-mortem report of the faulty update on Saturday. It blamed the issue on what the company calls a channel file update, which are special files that update the Falcon endpoint detection and response. That's EDR. That's what EDR stands for client with new techniques abused by threat actors. In this case it was channel file 291. And then he gives us you know the full file name, c-0000291, and then something you know, starsys that causes the crashes. Crowdstrike says this file is supposed to update the Falcon EDR to detect malware that abuses Windows named pipes to communicate with its command and control server. Such techniques were recently added to several C2 frameworks, tools used by threat actors and penetration testing teams, and CrowdStrike wanted to be on top of the new technique.
The company says the Falcon update file unfortunately yeah, unfortunately triggered a logic error Since Falcon ran in the Windows kernel. The error brought down the house and caused Windows to crash with a BSOD. After that it was just a house of cards. As the update was delivered to more and more CrowdStrike customers, the dominoes started falling all over the world. Kurtz, the CEO, was adamant on Friday that this was just an error on the company's part and made it explicitly clear that there was no cyber attack against its systems. Us government officials also echoed the same thing. For now, crowdstrike seems to be focused on bringing its customers back online.
The incident is likely to have some major repercussions going beyond the actual technical details and the global outages. Beyond the actual technical details and the global outages, what they will be? I cannot be sure he writes, but I smell some politicians waiting to pounce on it with some ideas he has in quotes. Oh great, this might also be the perfect opportunity slash excuse for Microsoft to go with Apple's route and kick most security vendors and drivers out of the kernel. But before that Microsoft might need to convince the EU to dismiss a 2009 agreement first. Per this agreement, microsoft cannot wall off its OS from third-party security tools. The EU and Microsoft reached this arrangement following an anti-competitive complaint filed by security software vendors after Microsoft entered the cybersecurity and AV market with Defender, with vendors fearing Microsoft would use its control over Windows to put everyone out of business by neutering their products. Doesn't this sound like well? No, sorry, we can't cancel third party cookies because some people are making money with them. Right, he writes.
After the recent Chinese and Russian hacks of Microsoft cloud infrastructure, we now know very well what happens when Microsoft has a dominant market position, and it's never a good thing. So the existence of this agreement isn't such a bad idea. If Microsoft wants to kick security software out of the kernel, defender needs to lose it too. Unfortunately, blinding security tools to the kernel now puts everyone in the iOS quandary, where everyone loses visibility into what happens on a system. That's not such a good idea either. So we're back with this argument where we started. In closing, just be aware that threat actors are registering hundreds of CrowdStrike-related domains that will most likely be used in spear phishing and malware delivery campaigns. They're so evil. It's, honestly, one of the best and easiest phishing opportunities we've had in a while. So, as suggested by this week's Picture of the Week, which shows the Windows kernel crash dump resulting from CrowdStrike's detection file update, I will be getting down to the nitty-gritty details that underlie exactly what happened, but I want to first finish laying out the entire story. The part of TechCrunch's coverage that I wanted to include was their writing.
This CrowdStrike, founded in 2011, has quickly grown into a cybersecurity giant. Today, the company provides software and services to 29,000 corporate customers, including around half of Fortune 500 companies, 43 out of 50 US states and eight out of the top 10 tech firms. According to its website, the company's cybersecurity software, falcon, is used by enterprises to manage security on millions of computers around the world, and now we know exactly how many millions. These businesses include large corporations, hospitals, transportation hubs and government departments. Most consumer devices do not run Falcon and are unaffected by this outage, and here was with that lead up. This was the point. One of the company's biggest recent claims to fame was when it caught a group of Russian government hackers breaking into the Democratic National Committee ahead of the 2016 US presidential election. Crowdstrike is also known for using memorable animal-themed names for the hacking groups. It tracks based on their nationality, such as Fancy Bear.
1:38:36 - Leo Laporte
Oh, that's where that came from.
1:38:54 - Steve Gibson
Oh, that's where that came from. And Charming Kitten believed to be an Iranian state-backed group. The company even makes action figures to represent these groups, which it sells as swag. Oh cool, crowdstrike is so big. It's one of the sponsors of the Mercedes F1 team and this year even aired a Super Bowl ad a first for a cybersecurity company.
1:39:24 - Leo Laporte
And they were also one of the first cybersecurity companies to advertise on this show, steve. In fact, we interviewed the CTO some time ago and it's an impressive company. You know, I'm very curious to hear what happened here. It's an impressive company.
1:39:39 - Steve Gibson
You know I'm very curious to hear what happened here. So, as I have here written, I have not counted the number of times this podcast has mentioned CrowdStrike it's certainly been so many times that their name will be quite familiar to everyone who's been listening for more than a short while, and not one of those previous mentions was due to some horrible catastrophe they caused. No, as the writer for TechCrunch reminds us, CrowdStrike has been quite instrumental in detecting, tracking and uncovering some of today's most recent and pernicious malware campaigns and the threat actor groups behind them. How are they able to do this? It is entirely due to exactly this same Falcon sensor instrumentation system that's been spread far and wide around the world.
It's this sensor network that gives them the visibility into what those 8.5 million machines that had been running it are encountering day to day in the field exactly, and we need that visibility, yeah by the way, here is this is here's the aquatic panda figurine for only 28 on the CrowdStrike swag shop. Wow, you've got to be really deep into that, whatever.
1:41:05 - Leo Laporte
Wow, I want a fancy bear.
1:41:08 - Steve Gibson
Okay, sorry, okay so this is not to in any way excuse the inexcusable. Make no mistake that what they just caused to happen was inexcusable. Make no mistake that what they just caused to happen was inexcusable. But any coherent answer to the question what is CrowdStrike and why in the world are we putting up with them? Should in fairness acknowledge that the same network that just crippled much of the world's cyber operations has also been responsible for discovering malicious activities and protecting not only their own customers but all of the rest of us as well. Catalin referred to George Kurtz, late of McAfee and now CrowdStrike's founder and CEO. George's note about this was addressed to quote valued customers and partners. He wrote I want to sincerely apologize directly to all of you for today's outage.
All of CrowdStrike understands the gravity and impact of the situation. We quickly identified the issue and deployed a fix allowing us to focus diligently on restoring customer systems as our highest priority. The outage was caused by a defect found in a Falcon content update for Windows hosts. Mac and Linux hosts are not impacted. This was not a cyber attack. This was not a cyber attack. We're working closely with impacted customers and partners to ensure that all systems are restored so you can deliver the services your customers rely on.
Crowdstrike is operating normally and this issue does not affect our Falcon platform systems. There's no impact to any protection via the CrowdStrike blog. Please continue to visit these sites for the latest updates. We've mobilized all of CrowdStrike to help you and your teams. If you have questions or need additional support, please reach out to your CrowdStrike representative or technical support.
We know that adversaries and bad actors will try to exploit events like this. I encourage everyone to remain vigilant and ensure that you're engaging with official CrowdStrike representatives. Our blog and technical support will continue to be the official channels for the latest updates. Nothing is more important to me than the trust and confidence that our customers and partners have put into CrowdStrike commitment to provide full transparency on how this occurred and steps were taking to prevent anything like this from happening again. George Kurtz, crowdstrike founder and CEO, and with that this podcast, can now dig in to some of the interesting and more technical nitty gritty. That will answer some of the interesting and more technical nitty-gritty. That will answer all of the remaining questions. Leo, let's take our final break and then we're going to do that all right, fascinating stuff.
1:44:31 - Leo Laporte
Uh, I wonder how, if crowd strike ever will really tell us what happened in a greater detail than they have. But uh, the.
1:44:40 - Steve Gibson
The industry has reverse engineers that I'll be talking about shortly. Oh, good.
1:44:44 - Leo Laporte
Okay, well, that's one way to find out Good. All right, we'll get to that in a moment. First, though, a word from one of our sponsors, actually a newer sponsor. I love these guys, big ID. They are the leading DSPM solution, data Security, posture Management and this is where DSPM is data security, posture management, and this is where DSPM is done differently.
Dspm, if you don't know, you probably do if you're in an enterprise or in IT. It centers around risk management and how organizations need to assess, understand, identify and, importantly, remediate data security risks across their data. Bigid seamlessly integrates with your existing tech stack and allows you to coordinate security and remediation workflows, but it also helps you know where your data is, who's got access to it. It's very powerful. You can uncover dark data, data that's otherwise not visible. You can identify and manage risk. You can remediate the way you want and you can scale your data security strategy. You can take action on data risks, whether it's to annotate, delete, quarantine or more, based on the data, all while maintaining an audit trail.
So many people use DSPM from BigID. Partners include ServiceNow, palo Alto Networks, microsoft, google, aws and more. In fact, one of their customers, the United States Army. You can imagine how much data the Army has to manage, right? Bigid equipped the US army to illuminate dark data, to accelerate their cloud migration, to minimize redundancy tough job in the army to minimize redundancy and to automate data retention. Us army training and doctrine command uses it.
They say the first this isa direct quote. By the way, the first wow moment with BigID came with just being able to have that single interface that inventories a variety of data holdings, including structured and unstructured data, across emails, zip files, sharepoint databases and more. I mean parenthetically. They must have the most kind of heterogeneous collection of data of any company, any group in the world. Right, it's the US Army. To see that mass I'm going on with a quote and to be able to correlate across those is completely novel. They never had this. Before they finish the quote. This is again from US Army Training and Doctrine Command. I've never seen a capability that brings us together like Big ID does. That's a big, big recommendation.
With Big ID's advanced AI models, you can reduce risk, accelerate time to insight and gain visibility and control over all your data. If the US Army Training and Doctrine Command can do it, you can do it. Cnbc recognized Big ID as one of the top 25 startups for the US Army Training and Doctrine Command can do it, you can do it. Cnbc recognized BigID as one of the top 25 startups for the enterprise. They were named the Inc 5000 and the Deloitte 500 two years in a row. They are the leading modern data security vendor in the market today. You must know the name by now, and if you don't, you've got to check it out.
Listen to what the publisher of Cyber Defense Magazine says about Big ID. Big ID this is a quote embodies three major features we judges look for to become winners Understanding tomorrow's threats today, providing a cost-effective solution and innovating in unexpected ways that can help mitigate cyber risk and get one step ahead of the next breach. Start protecting your sensitive data where your data lives at bigidcom slash security now. Get a free demo. You'll see how BigID can help your organization reduce data risk and accelerate the adoption of generative AI. By the way, that's also an important part of using Gen AI is knowing what data to train on and what not to right. What data should not be the AI should not be allowed to see. Big ID can help with that too. That's bigidcom slash security now. They have a lot of white papers. They're big on information lots of informational resources there. Even if you're not a customer, there's a free new report that provides valuable insights and key trends on issues like AI adoption, the challenges and overall impact of JNI across organizations. This is a must read.
Bigidcom slash security now B-I-G-I-D. Bigidcom slash security now big id. Big id dot com slash security now. This is an example of a company we always look forward to the ability to introduce you to companies that deserve your attention. This is a perfect example of it. These are the. These are the leaders in this. Big id dot com slash security now. All right, so a little reverse engineering and maybe we can figure out what happened here. I mean the email you read a few emails ago is the question everybody's asking how could a company do this? How could they not have tested? How could they not know? But to understand that, we need to understand what happened.
1:49:59 - Steve Gibson
Right.
And that's your job Okay so let's begin with CrowdStrike's predictably not very technical update, which they titled Falcon Update for Windows Hosts Technical Details and I'm doing this because I need to establish the context for what we're going to talk about next. So they asked themselves the question what happened? And they answer. On July 19, 2024, at 4.09 UTC, as part of ongoing operations, crowdstrike released a sensor configuration update to Windows systems. Sensor configuration updates are an ongoing part of the protection mechanisms of the Falcon platform. This configuration update triggered a logic error resulting in a system crash and blue screen BSOD. They actually said that on impacted systems, the sensor configuration update that caused the system crash was remediated on Friday, july 19, 2024, at 527 UTC. So 409, it happened, 527, they fixed it. Of course, the damage was done. Right, if you're stuck in a boot loop, you can't update yourself. They said this issue is not the result of or related to a cyber attack. Customers running Falcon Sensor for Windows version 7.11 and above that were online between Friday at that 409 UTC and up to 527 when they fixed it. May be impacted Systems running Falcon sensor for Windows version 7.11 and above that downloaded the updated configuration from again those same two times were susceptible to a system crash. Yeah, no kidding, find somebody who doesn't know that. Okay then, configuration file primer.
However you want to pronounce it, the configuration files mentioned above are referred to as channel files and are part of the behavioral protection mechanisms used by the Falcon sensor. Updates to channel files are a normal part of the sensor's operation and incur several times a day in response to novel tactics, techniques and procedures. You know TTPs discovered by CrowdStrike. This is not a new process. The architecture has been in place since Falcon's inception. Then technical details on Windows systems channel files reside in the following directory. It's C colon, backslash Windows, backslash system 32, backslash drivers, backslash CrowdStrike. So they have their own subdirectory under drivers with capital C hyphen. Then they said each channel file is assigned a number as a unique identifier. The impacted channel file in this event is 291, and will have a file name that starts with C hyphen 00000291 hyphen and ends with a dot sys extension. Although channel files end with a sys extension, they are not kernel drivers. Channel file 291 controls how Falcon evaluates named pipe execution, and I'll talk about that in a second. On Windows systems. Named pipes are used for normal interprocess inter-system communication in Windows.
The update that occurred at 409 UTC was designed to target newly observed malicious named pipes being used by common C2 framework. You know command and control frameworks in cyber attacks. The configuration update triggered a logic error that resulted in an operating system crash. Update triggered a logic error that resulted in an operating system crash. Crowdstrike has corrected the logic error by updating the content in channel file 291. No additional changes to channel file 291 beyond the updated logic will be deployed, meaning they're not changing their driver.
Falcon is still evaluating and protecting against the abuse of named pipes. This is not related to null bytes contained within channel file 291 or any other channel file. That was another you know specious rumor that took hold on the Internet that the file was all nulls. The most up-to-date remediation recommendations and information can be found on our blog or in the support portal. Recommendations and information can be found on our blog or in the support portal. We understand that some customers may have specific support needs and we ask them to contact us directly. Systems that are not currently impacted will continue to operate as expected, continue to provide protection and have no risk of experiencing this event in the future. Systems running Linux or Mac OS do not use channel file 291 and were not impacted, and they finish with this root cause analysis. They said we understand how this issue occurred and we are doing a thorough root cause analysis to determine how this logic flaw occurred. This effort will be ongoing. We are committed to identifying any foundational or workflow improvements that we can make to strengthen our process. We will update our findings in the root cause analysis as the investigation progresses.
Okay, so now we have a comprehensive understanding of what happens to today's truly IT-dependent global operational existence. Extra specially secured and running Windows OS based machines are all caused to spontaneously crash and refuse to return to operation. It's not good. I was unable to use my mobile app to remotely order up my morning five shots of espresso from Starbucks. This is unacceptable. Something must be done Before we address the most burning question of all, which is how CrowdStrike and their systems could have possibly allowed something so devastating to occur. Allowed something so devastating to occur? Let's first answer the question of why Windows' own recovery systems were also unable to be effective in recovery from this.
Many years ago, this podcast looked at a perfect example of a so-called rootkit in the form of Sony Entertainment's deliberately installed DRM digital rights management software. We saw how a normal directory listing of files could be edited on the fly to remove all visibility of specific files, turning them into ghosts. The files were there, but we could not see them. Sony's programmers did that to hide the presence of their own DRM. That Sony rootkit demonstrated that we could not believe our own eyes, and it perfectly drove home just how much we depend upon the integrity of the underlying operating system to tell us the truth. We take for granted that when we ask for a file listing, it's going to show all of them to us. Why would it lie? Why, indeed, if malware of that sort is able to infect the core operation of an operating system, then it's able to hide itself and strongly protect itself from both discovery and removal. That was Sony's goal with their rootkit. This fact creates a competition between the good guys and the bad guys to get in and establish the first foothold in an operating system, because the entity that arrives on the scene first is able to use its placement to defend itself from anything that might happen afterwards.
For that reason, the actual CrowdStrike pseudo-device driver not the mistaken channel file, but the actual driver that later reads those channel files which Microsoft themselves previously examined, approved and digitally signed examined, approved and digitally signed was given the highest honor of being flagged as a boot start device. Microsoft's own documentation says, quote a boot start driver is a driver for a device that must be installed to start the Microsoft Windows operating system. Unquote. In other words, once device driver code is present containing that boot start flag, windows is being told and believes that it must load that driver in order to successfully start itself running. For all it knows, that driver is for the mass storage RAID array that contains Windows itself. And if that driver is not installed and running by the time the motherboard firmware has finished loading the various pieces, windows will be unable to access its own mass storage. So Windows may not know why, but it does know that a device driver that carries a valid Microsoft digital signature that has the boot start designation must be loaded. So it will be loaded and initialized in order for Windows to successfully boot. And this brings us to CrowdStrike's BootStart driver.
Crowdstrike's engineers designed a powerful driver that's designed to significantly augment Windows' own anti-malware defenses. When it's loaded into Windows it hooks many of Windows' application programming interface, you know API functions. What this means is that it places itself in front of Windows so that any code that would normally ask Windows to do something on its behalf will instead be asking CrowdStrike's code, and only if CrowdStrike sees nothing wrong with the request will CrowdStrike in turn pass that application's request on to Windows. It creates a defensive wrapper shell around the Windows kernel, and if this sounds exactly like what a rootkit does, you would be right. Crowdstrike's driver kit is in the root. It needs to to get its job done.
What little we've learned about the specifics of this CrowdStrike failure is that it involved named pipes, and that again makes sense, since named pipes are used extensively within Windows for inter-process communications. It's pretty much the way clients obtain services, that the on-the-code or the on-the-fly code signing service which I created before the release of Spinrite 6.1, is started by Windows after it finishes booting. When that service starts up the one I created it uses the Windows API to create a named pipe with a unique name. Then later, when a user purchases a copy of Spinrite, grc's web server opens a dynamic connection to the code signing service by opening a named pipe of the same name. This deliberate name collision connects the two separate events to establish a highly efficient interaction which allows the service and its client to then negotiate the details of what needs to be done.
Crowdstrike told us that malware had been seen using the Named Pipes API for communication with its command and control servers. So they needed to hook Windows Named Pipes API in order to monitor the system for and to possibly block that activity. And clearly something went terribly wrong, for reasons that CrowdStrike is still being silent about. The presence of this channel file caused a bad parameter to be passed to a function. This week's picture of the week is a snapshot of the crash event that brought down all of those 8.5 million Windows machines.
We see a procedure being called with two parameters. The first parameter is zero and the second parameter has the value of hexadecimal 9C, 9, charlie which is decimal 156. That value of 156 is loaded into the CPU's R8 register, where it's then used as a pointer to point to the value in question. So then the CPU is asked to load the 32-bit value from that location into the CPUs are nine register. The only problem is the way the system's memory is mapped. There's nothing, no memory located at location 156. The processor, realizing that it has just been asked to load 32 bits of memory that does not exist, figures that something must have gone very, very wrong somewhere.
2:04:31 - Leo Laporte
So it panics and Steve doesn't get his venti latte. It's just that simple.
2:04:35 - Steve Gibson
I can't get my five shots, I have to actually show up in person. It's like the pilgrims Leo. Suddenly we're reduced to fighting Indians. It's not really funny.
2:04:48 - Leo Laporte
I mean some people got stranded for two or three days in the airport in.
2:04:53 - Steve Gibson
Atlanta Well, and IT admins lost their jobs. There were people fired because they were blamed for this.
2:04:58 - Leo Laporte
Oh, that's sad, that's really sad. Yes, no one should be blamed for this. Oh, that's sad, that's really sad. Yes, no one should be blamed for this, except CrowdStrike, I guess. So it's interesting. So it jumped to it. Kernel panicked because it jumped to an area of memory that doesn't exist. That's what a machine is supposed to do. That's what a blue screen does. That's the whole point.
2:05:15 - Steve Gibson
The kernel? Yes, the kernel panics and it declares an emergency.
2:05:20 - Leo Laporte
It's over.
2:05:20 - Steve Gibson
Yeah, right, yes. Now, what I've just described is a very exactly as you said, leo, a very typical series of events which precipitates what the entire world has come to know as the blue screen of death. Yeah, it's something that should never happen, but hardware is not perfect, and neither are people.
2:05:41 - Leo Laporte
And I've seen it. It's a green screen on the Mac. It's a black screen on Linux, so every operating system does this. There's no reasonable way to recover from a failure like that.
2:05:54 - Steve Gibson
Things that are not supposed to ever happen. Happen anyway is the point. And just to be clear, if an application running on top of the Windows operating system as one of its client applications were to ever ask the processor to do something impossible like read from non-existent memory or divide by zero, windows could and would just shrug it off and allow the app to crash. Windows might display some mumbo-jumbo on the screen that would be entirely meaningless to the app's user, but life would go on without any other app in the system caring or being the wiser. The crucial difference is where this unrecoverable error occurs. When it occurs deep within the operating system kernel itself, there's no one to call it's game over, and the thing that gets terminated is the operating system itself. Now we do not know exactly where that aberrant value of 156 came from. There's been speculation that that it looks like an offset into a structure and that would. That would make sense, so that if the structure's pointer itself were null, an offset like this might result and then be fed to a function that was expecting to be pointing to a member of a valid object, instead of out into hyperspace. Some have observed that CrowdStrike's channel file contains nulls, but the unsatisfying reality is that all we have today is conjecture. There is no question that CrowdStrike definitely and absolutely already knows exactly what happened, but they're not saying I have absolutely zero doubt that their corporate attorneys clamped down the cone of silence over CrowdStrike so rapidly and forcibly that no one inside CrowdStrike even dares to mumble about this in their sleep. I mean, this is you know. To say that there will be repercussions is got to be the the uh, you know, just doesn't even begin. Okay, there is very likely good news on that front. However, that is what actually happened. Crowd strikes driver and it's associated channel file two, nine, one, now infamous, which together triggered this catastrophe, still exist in the world, and the world contains a great many curious engineers. Exactly what happened at at least at the client end, but it will not be forthcoming from CrowdStrike, and it won't need to be, because we're going to figure this out as an industry.
But now we face the final, biggest question of all, which is how could CrowdStrike or any other company for that matter, having as much at stake and to lose from being the proximate cause of this incredibly expensive, earth-shaking catastrophe possibly have allowed this to happen? That everyone wants to know is how could CrowdStrike have possibly allowed this defective channel 291 file to ever be deployed at all? And when I say that, everyone wants to know, that now of course includes members of the United States Congress who are demanding that George Kurtz present himself before them on his knees with his head bowed and his neck exposed. I have a theory. Not long ago, just a few months ago, microsoft asked us to believe that, at an incredibly unlikely, credulity-stretching chain of events as I recall, it was five unlikely failures, each of which were required for a private key to leak, enabled a malicious Chinese actor to obtain Microsoft's private key, which led to that large and embarrassing Outlook 365 email compromise. Assuming that all of this was true, it's clear that so-called black swan events can occur, no matter how unlikely they may be. So one view of this is that CrowdStrike does indeed have multiple redundant systems in place to guard against exactly such an occurrence. After all, how could they not? Yet, as we're told, happened to Microsoft? Despite all of that, something was still able to go horribly wrong.
But I said one view above, because there's another possibility. It's not outside the box to imagine that this particular failure path, whatever it was, was actually never expected or believed to be possible by the systems designers. So there may not actually have been any pre-release sandbox sanity testing being done to those multiple times per day malware pattern updates that CrowdStrike was publishing to the world. And remember that CrowdStrike had been doing this successfully and without any massive incident such as this for many, many years successfully and without any massive incident such as this, for many, many years Now. I understand that. To someone who does not code, like those in the US Congress, this is going to sound quite netty, but developers typically only test for things that they know or imagine might possibly go wrong. If a coder adds two positive numbers, they don't check to make sure that the result is greater than zero, because it must be. So I would not be surprised to learn that what happened slipped past CrowdStrike's own sanity-checking verifiers, because it was something that was not believed to be possible.
And while now, yes, a final last-stage sanity check against live systems prior to deployment seems like the obviously important and necessary addition, either it must not have seemed necessary and hasn't ever been in the past, or it is present and nevertheless it somehow failed, much as those five sequential and separate failures within Microsoft allowed their closely held secret to escape. Also, we don't know exactly what sort of CDN you know content delivery network they're using. If 8.5 million instances of their device driver are reaching out for more or less continual updates 24-7, they're likely using some distribution network to spread those updates. What if everything was good at CrowdStrike's end but the upload of that file to the cloud somehow glitched during transit, allowing that glitched file to then be distributed to the world's Windows machines? Of course we have means for protecting against this too Digital signing by the authorized sender and signature verification by the recipient. We would certainly hope that these updates are signed, and any failure of signature verification would prevent the file's use. But we've seen that not happening too in the past. So distribution failure, should you know, we would hope it does not explain the trouble, but it might.
I'll finish with the acknowledgment that what has happened is so bad that I doubt we're going to soon learn the truth from CrowdStrike. He wrote we understand how this issue occurred and we are doing a thorough root cause analysis to determine how this logic flaw occurred. This effort will be ongoing. Okay, that's just gibberish. You say you understand how this issue occurred because you don't want to seem totally incompetent, but you're not sharing that understanding because you're too busy determining how it occurred. Right Again, I expect that our industry's beloved reverse engineers will have a great deal to share long before CrowdStrike's attorneys finish proofreading and massaging the carefully worded testimony which George Kurtz will soon be delivering in front of Congress.
2:15:33 - Leo Laporte
So really, any number of things could have happened. It's hard to ascribe blame if you don't know. They may have done testing and it could have been a flaw in the CDN. So yeah, we just need to hear more from them. Probably won't, probably won't.
2:15:52 - Steve Gibson
Yeah, I've heard reports, again unconfirmed, that the files are not signed. If the files are not signed, the files are not signed. That's a crime. Yeah, because if that's true, it would mean that it would be possible for a glitch in this in the content, like a transmission glitch in the content delivery system, to cause this or a miscreant in the middle to stick another one in the middle yeah, that that you know. You really we can't rule that out and I do blame.
2:16:21 - Leo Laporte
Microsoft a little bit. I guess they blame the EU. But to allow an interpreter to run in ring zero and then to allow these unsigned files if they're unsigned to run in the interpreter is a very risky proposition, right? Interpreter is a very risky proposition, right? You've talked all along about how interpreters are the number one cause for craft, for these problems yes, and the other thing too, is we, we again, I, I.
2:16:53 - Steve Gibson
if I didn't have a day job, I would be looking around for a copy of this file. Yeah, the burning question to me is whether there's executable code in this. It may not itself be an executable file, but it could have, for example, but Falcon is an interpreter. I think Okay, so then it contains P code Right, and the P code could have been bad and that caused a problem in the interpreter. Right and and the P code could have, you know, been been bad, right and, and that caused a problem in the interpreter.
2:17:24 - Leo Laporte
So Right, yeah, so you know it's a. These systems are basic. It's not quite an antivirus signature, but it's basically the same idea, which is they are.
2:17:38 - Steve Gibson
It has to do behavioral analysis.
2:17:40 - Leo Laporte
Exactly Behavioral analysis requires more of an algorithmic approach it's heuristic, yes, so it has to be more of a program than let's look for a string, and so I think that's the thesis is that these little sensors are P-code and that this way, basically, you have a security system running in ring zero that can be modified on the fly.
2:18:01 - Steve Gibson
Yes.
2:18:02 - Leo Laporte
Yes, problem Right there.
2:18:04 - Steve Gibson
Dangerous.
2:18:05 - Leo Laporte
Dangerous and you might, you know, the Falcon can be signed Probably. I'm sure the Falcon is signed. It wouldn't run in Ring Zero.
2:18:11 - Steve Gibson
Microsoft signed the Falcon driver yeah, of course. Because you can't run in the kernel unless it's blessed by Microsoft.
2:18:24 - Leo Laporte
Now, one of the things we talked about on MacBreak Weekly is that Apple has very carefully but fairly aggressively removed the ability to put kernel extensions into macOS for this very reason. Right, they're not required to by the EU. You know, nobody's saying Apple's not big enough for anybody to say, well, you've got to allow these security guys to put stuff in the kernel. There are ways around it. You can run kernel extensions, but it takes. You have to jump through a lot of hoops and Apple basically disallows it, and they've been slowly moving in that direction.
2:18:52 - Steve Gibson
It might be that the upshot of this is another level of disaster recovery, which Microsoft has not yet implemented Because you know it did. The fact that it turned the screen blue and put up some text means that something was still alive.
Yes, so you know, I mean, and what happens is an exception is created when you try to read from non-existent memory. That exception goes to code, that is an exception handler, and what it could do is set something that then causes a reboot into a different copy of the os, for example. I mean, they, they could, you know, or, as, as as we know, you could reboot under a manually forced safe mode in order to keep that Falcon driver from running.
2:19:41 - Leo Laporte
And I think a number of people recommended that that this would be an not easy, but this would be an implementable solution which is, if something caused a crash, you don't load it on the next boot and see what happens. Then I can see problems with that also, but I think that something will have to be done.
2:20:02 - Steve Gibson
Well, yes, for example, if it was the system's RAID array driver.
2:20:06 - Leo Laporte
Right, that's not going to work, obviously yes, but if it's a third-party signed driver, I mean, any driver can do this. By the way, drivers generally do run in ring zero because that's how you talk to the hardware. But remember, microsoft created HAL, the hardware extraction layer, for that very reason, so that you could talk to a variety of hardware and you didn't have to operate at such a low level. Their own interpreter, in effect. In effect, I don't know, it's very, it's uh, it seems solvable, but we, but I, obviously I don't have enough information to know what really happened.
2:20:47 - Steve Gibson
So well, no one does, no one they're not saying and they're not going to say to, I mean, their, their entire existence is hanging by a thread at the moment. Oh yeah, yeah, I mean this was a big deal. And they're going to have to explain, not only to Congress but to the world, exactly what, what this root cause nonsense is.
2:21:08 - Leo Laporte
Well, that's one of the reasons you and I have both for a long time said end users should not be running antivirus software because, as a necessity, it runs at a low level and has permissions that normal software doesn't, and we've seen it again and again that that can become a vector for malware. Yeah, there's no evidence that this was intentional or malware, though at this point.
2:21:33 - Steve Gibson
None, None. There's no evidence either way. You know, they of course don't want it to be a cyber attack. They don't want it to be a cyber attack, they don't want it to be deliberate. But they haven't yet explained how a bad file got out to eight and a half million machines.
2:21:45 - Leo Laporte
They're in a bad position because it's either stupidity, incompetence or a bad guy. I mean, it's hard. That's why they haven't said anything right, because if they tell us what really happened, it's very possible people will say, well, that was dumb. Yeah. I think if there were a good excuse, they would have said what it was already Right, right, right.
2:22:11 - Steve Gibson
Oh, it got corrupted in the CDN. This will not be the last time we are talking about CrowdStrike.
2:22:14 - Leo Laporte
Yeah, it's you know, and, as you pointed out early on, they were the good guys. They are the good guys, they are the good guys. They do good work, oh my.
2:22:22 - Steve Gibson
God. The power of that sensor network is the way we are finding bad guys on a global scale. They are absolutely. You know we need them there. They just tripped up Right.
2:22:39 - Leo Laporte
I talked to the CTO. That's exactly what we talked about is their sensor network and how, how many billions of signals they got. You know some huge number every minute. It's astonishing.
2:22:49 - Steve Gibson
Yeah.
2:22:49 - Leo Laporte
And it was so valuable because they could see threats in real time as they happened. Catch zero days right then. This is fascinating. Thank you. As always, steve does a great job explaining this, and I was waiting all weekend to get here and find out what Steve had to say. If you like this show, help Steve out, help us out. We want to keep doing it to 999 and beyond, but we need your help to do that. We need you to join Club Twit. If you're not yet a member, it is only $7 a month. There's a lot of benefits, including ad-free versions of this show and all our other shows and access to the Discord and going forward. I've mentioned this before, but we're kind of reinventing what we do. Our community is so important and I want to give the community more access to our hosts. I haven't even mentioned this to Steve yet, but with the new studio set up, we should be able to go live more often and I was thinking Friday morning man, I wish I had that studio up, because I would call Steve and we would get on and we would say you know, whatever information we had get some IT pros on who are actually dealing with it on the ground. We could have covered this live and I think we would have done a better job than mainstream media. And that's what I want to do. Join the club, help us do that. $7 a month. Twittv, slash Club, twit. You can give more if you wish.
Steve Gibson is at GRCcom. That's where you'll find his bread and butter, which is Spinrite, the world's finest mass storage, performance enhancer, recovery solution, maintenance solution. Is there anything it doesn't do? If you've got a mass storage, you need Spinrite. 6.1 is the new version. It's out now. You can get it at GRCcom. While you're there, you can also get a copy of this show. Steve has a whole section devoted to security now, including not only the 64-kilobit audio version. He has a 16-kilobit audio version for the bandwidth impaired, one of whom was our transcriptionist, elaine Ferris, who lives out in a ranch in the middle of nowhere, so he made a small version for her. In return, she gives us a great text version of the show, so he's got transcripts there. He also has his show notes with the picture of the day and all the other stuff.
You don't have to. You can't get them mailed to you, but you don't have to. You can just go to GRCcom If you do want them mailed to you. Join Steve's mailing lists, or, at least you know, just validate your address so that you can email him directly by going to GRCcom slash email. You don't have to get the lists. You know, it's fact. This is so, steve Gibson. It's off by default, but I think there are a lot of people who would like that box checked, so if you want to check it, do.
We have, of course, 64 kilobit audio on our website, but we also have the video. We make that available at twittv slash sn. There is a youtube channel with the video as well, dedicated to security. Now, uh, there is also uh, you know the podcast feed you can subscribe in your favorite podcast player, excuse me, and get it automatically the minute we are done, well, the minute we edit it out and put it out, uh, you can watch us live too, too and this is new we have viewers now. It's so much fun to watch. I get to see all the different chats from YouTube, twitch, kik, facebook, xcom, linkedin and, of course and I mentioned YouTube and YouTube, youtubecom slash, twit slash live.
The show is live right after Mac break, weekly, that's Tuesday afternoon, usually around one 32 PM Pacific, that's a four, 30 Eastern, 2030 UTC. On all of those streams, we fire them up when the show begins. So do please, if you want to watch live. But even if you watch live, do us a favor and subscribe. That way you won't miss an episode. This is something you can't miss. Steve, have a great week. I hope it's a little calmer and we'll see you next Tuesday.
2:26:47 - Steve Gibson
There are things I couldn't get to, so we'll be doing a little catch up next week as well. See you then, buddy Bye. Security Now. Security now.